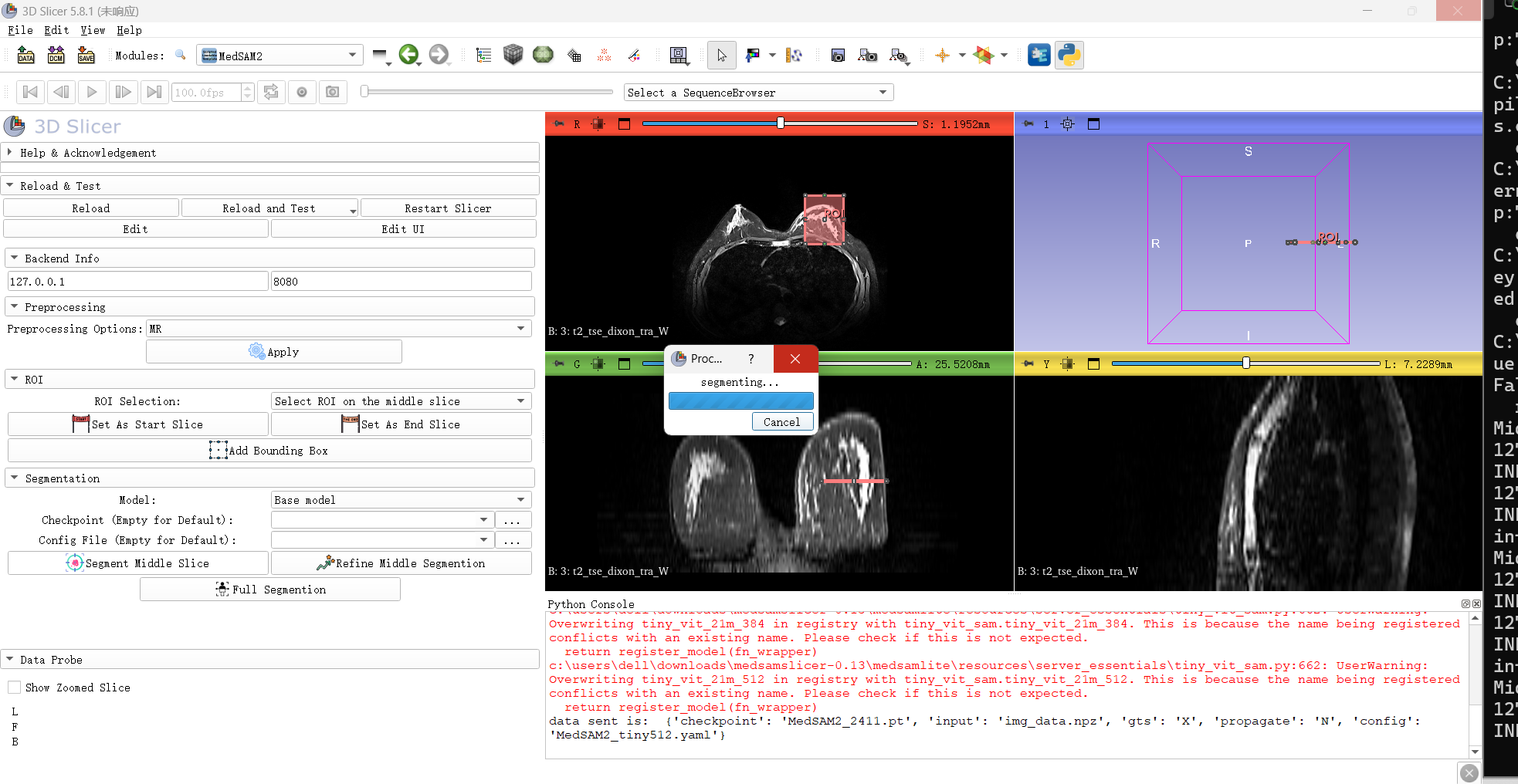
Hey! I have followed all the instruction to download and setup medsam2 pluggin in slicer. But the slicer just dead between segmentation and downloading results. I see the cmd line of python server running just all right. I have tried different models and all failed. What could be the problem?
The slicer just dead like this:
This is what shown in my miniconda prompt
(base) C:\Users\dell>cd C:\device\researches\Hepatoma\MRIV\MRIV - Code\SAM2\MedSAMSlicer
(base) C:\device\researches\Hepatoma\MRIV\MRIV - Code\SAM2\MedSAMSlicer>conda activate medsam2
(medsam2) C:\device\researches\Hepatoma\MRIV\MRIV - Code\SAM2\MedSAMSlicer>python server.py
* Serving Flask app 'server'
* Debug mode: on
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:8080
* Running on http://192.168.0.100:8080
Press CTRL+C to quit
* Restarting with stat
* Debugger is active!
* Debugger PIN: 477-329-984
127.0.0.1 - - [01/Jul/2025 15:15:32] "POST /upload HTTP/1.1" 200 -
infering img_data.npz
C:\device\researches\Hepatoma\MRIV\MRIV - Code\SAM2\MedSAMSlicer\sam2\modeling\sam\transformer.py:270: UserWarning: Memory efficient kernel not used because: (Triggered internally at C:\cb\pytorch_1000000000000\work\aten\src\ATen\native\transformers\cuda\sdp_utils.cpp:773.)
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
C:\device\researches\Hepatoma\MRIV\MRIV - Code\SAM2\MedSAMSlicer\sam2\modeling\sam\transformer.py:270: UserWarning: Memory Efficient attention has been runtime disabled. (Triggered internally at C:\cb\pytorch_1000000000000\work\aten\src\ATen/native/transformers/sdp_utils_cpp.h:558.)
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
C:\device\researches\Hepatoma\MRIV\MRIV - Code\SAM2\MedSAMSlicer\sam2\modeling\sam\transformer.py:270: UserWarning: Flash attention kernel not used because: (Triggered internally at C:\cb\pytorch_1000000000000\work\aten\src\ATen\native\transformers\cuda\sdp_utils.cpp:775.)
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
C:\device\researches\Hepatoma\MRIV\MRIV - Code\SAM2\MedSAMSlicer\sam2\modeling\sam\transformer.py:270: UserWarning: Torch was not compiled with flash attention. (Triggered internally at C:\cb\pytorch_1000000000000\work\aten\src\ATen\native\transformers\cuda\sdp_utils.cpp:599.)
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
C:\device\researches\Hepatoma\MRIV\MRIV - Code\SAM2\MedSAMSlicer\sam2\modeling\sam\transformer.py:270: UserWarning: CuDNN attention kernel not used because: (Triggered internally at C:\cb\pytorch_1000000000000\work\aten\src\ATen\native\transformers\cuda\sdp_utils.cpp:777.)
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
C:\device\researches\Hepatoma\MRIV\MRIV - Code\SAM2\MedSAMSlicer\sam2\modeling\sam\transformer.py:270: UserWarning: Expected query, key and value to all be of dtype: {Half, BFloat16}. Got Query dtype: float, Key dtype: float, and Value dtype: float instead. (Triggered internally at C:\cb\pytorch_1000000000000\work\aten\src\ATen/native/transformers/sdp_utils_cpp.h:110.)
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
C:\Users\dell\miniconda3\envs\medsam2\Lib\site-packages\torch\nn\modules\module.py:1747: UserWarning: Flash Attention kernel failed due to: No available kernel. Aborting execution.
Falling back to all available kernels for scaled_dot_product_attention (which may have a slower speed).
return forward_call(*args, **kwargs)
Middle Slice Mask Calculated
127.0.0.1 - - [01/Jul/2025 15:15:38] "POST /run_script HTTP/1.1" 200 -
INFO:werkzeug:127.0.0.1 - - [01/Jul/2025 15:15:38] "POST /run_script HTTP/1.1" 200 -
see also in Issues · bowang-lab/MedSAMSlicer